library("moderndive") #for get_regression_table()
library("tidyverse")
df_raw <- readr::read_csv("air_quality_demo_data.csv")
# brand colors
# orange on white: #e77500
# orange on black: #f58025Warm-Up
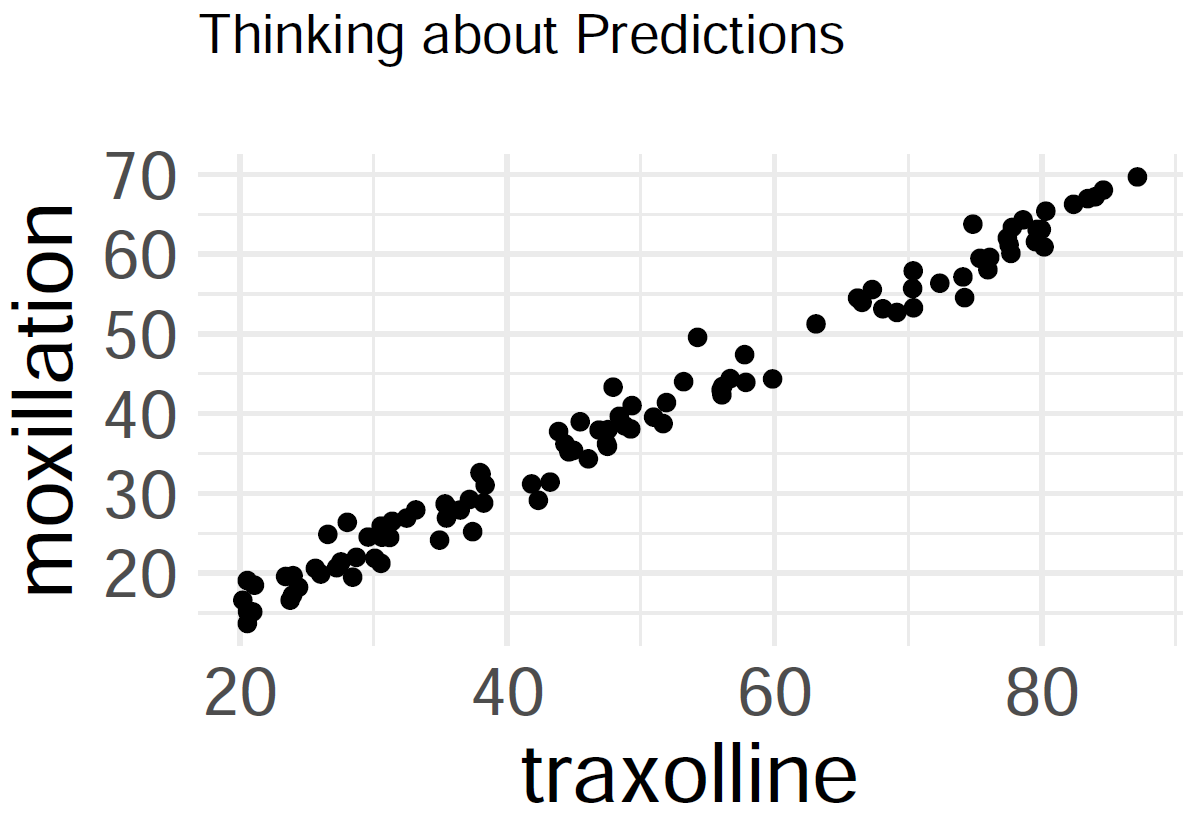
On Predictions
Predict how much moxillation takes place at 70 traxolline.
Setting
Tidyverse
Data
This data set can be seen at aqicn.org and was accessed through the PurpleAir API
head(df_raw)# A tibble: 6 × 6
time_stamp humidity temperature pressure pm1.0_atm pm2.5_atm
<dttm> <dbl> <dbl> <dbl> <dbl> <dbl>
1 2023-06-10 06:00:00 34.3 81.3 1004. 0.355 0.64
2 2023-06-10 12:00:00 30.8 85.0 1003. 8.78 12.6
3 2023-06-10 18:00:00 26.9 88.6 1003. 18.2 26.7
4 2023-06-11 00:00:00 37.0 82.0 1005. 19.2 28.9
5 2023-06-11 06:00:00 49.7 73.6 1006. 27.9 43.0
6 2023-06-11 12:00:00 33.6 89.5 1006. 27.7 41.7 - about 10 weeks of weather data, at 6-hour intervals (
- query: Why do we record different types of particulate matter measurements?
Wrangling
df <- df_raw |>
separate(time_stamp, into = c("date", "time"),
remove = FALSE, sep = " ") |>
mutate(time = ifelse(is.na(time), "00:00:00", time),
day_part = case_when(
time == "06:00:00" ~ "morning",
time == "12:00:00" ~ "noon",
time == "18:00:00" ~ "evening",
.default = "midnight"
)) |>
rename(pm1_0 = pm1.0_atm, pm2_5 = pm2.5_atm) |>
select(time, day_part, humidity, temperature, pm2_5)separatethe time stamp intodateandtimecolumns- described parts of the day: morning, noon, evening, midnight
- renamed particulate matter columns for ease
head(df)# A tibble: 6 × 5
time day_part humidity temperature pm2_5
<chr> <chr> <dbl> <dbl> <dbl>
1 06:00:00 morning 34.3 81.3 0.64
2 12:00:00 noon 30.8 85.0 12.6
3 18:00:00 evening 26.9 88.6 26.7
4 00:00:00 midnight 37.0 82.0 28.9
5 06:00:00 morning 49.7 73.6 43.0
6 12:00:00 noon 33.6 89.5 41.7 Linear Regression
- response variable (
- predictor variable (
- context: levels above 35 micrograms per cubic meter are considered unhealthy (according to the Indoor Air Hygiene Institute)
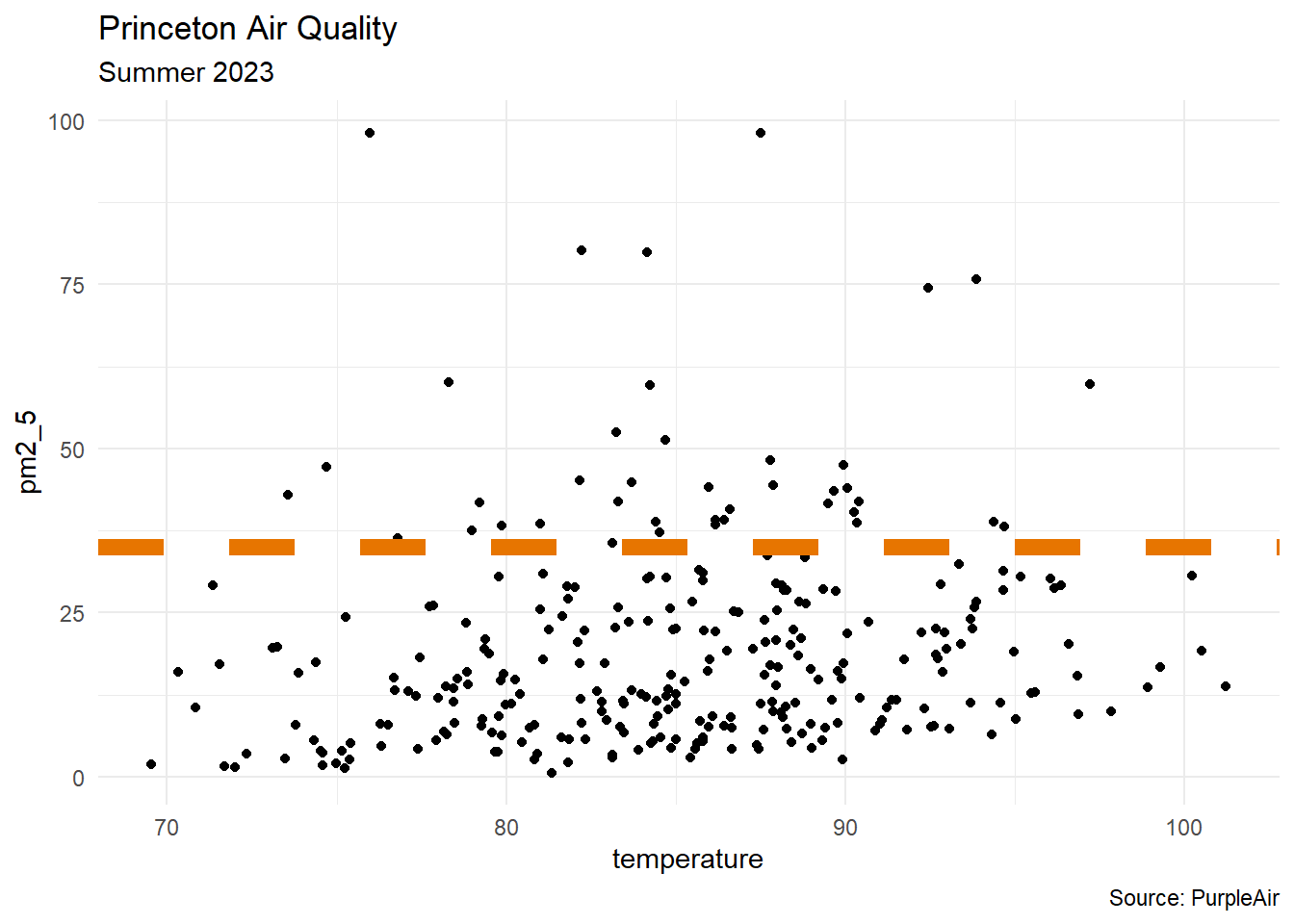
df |>
ggplot(aes(x = temperature, y = pm2_5)) +
geom_point() +
geom_hline(yintercept = 35, color = "#e77500",
linewidth = 3, linetype = 2) +
labs(title = "Princeton Air Quality",
subtitle = "Summer 2023",
caption = "Source: PurpleAir") +
theme_minimal()Where Fit?
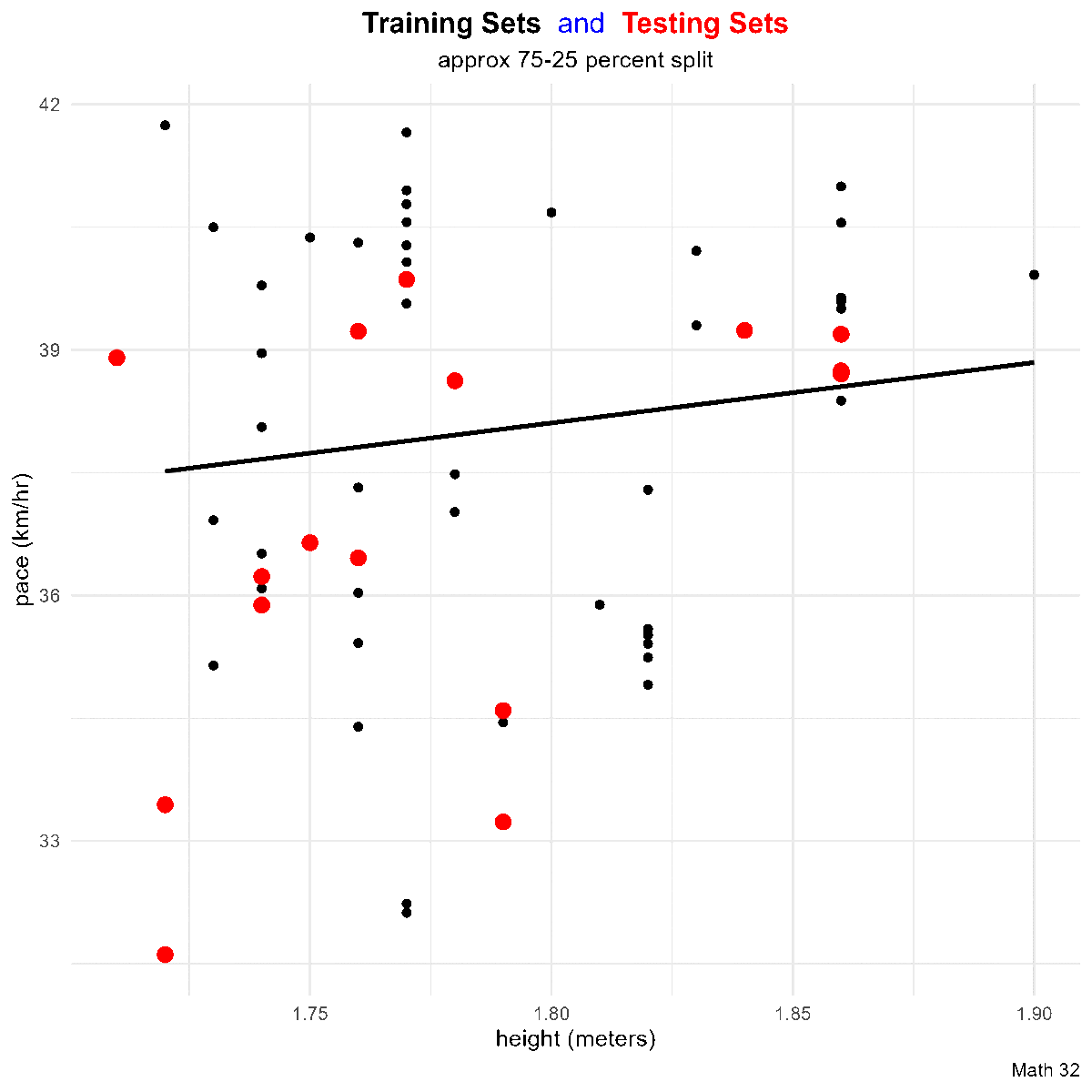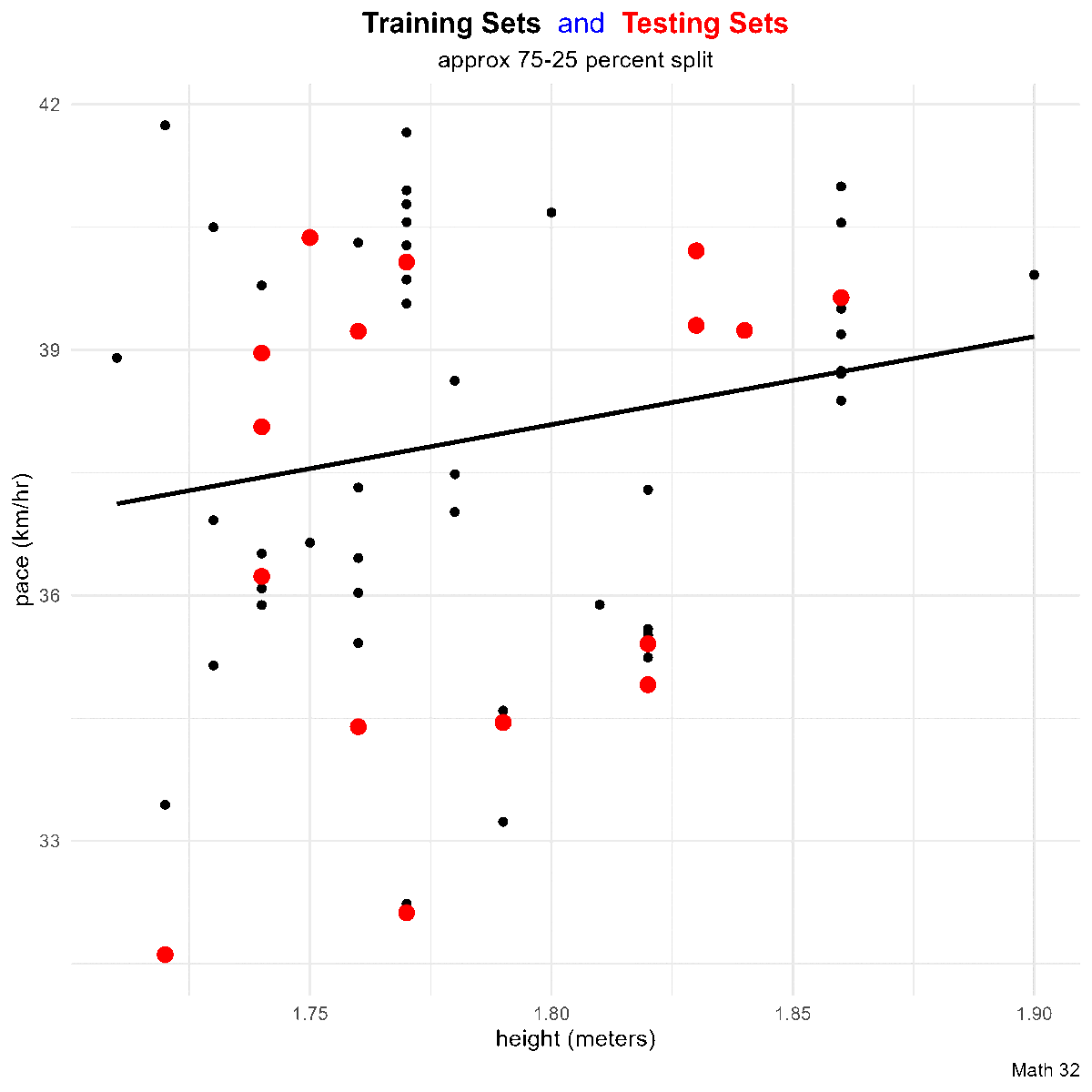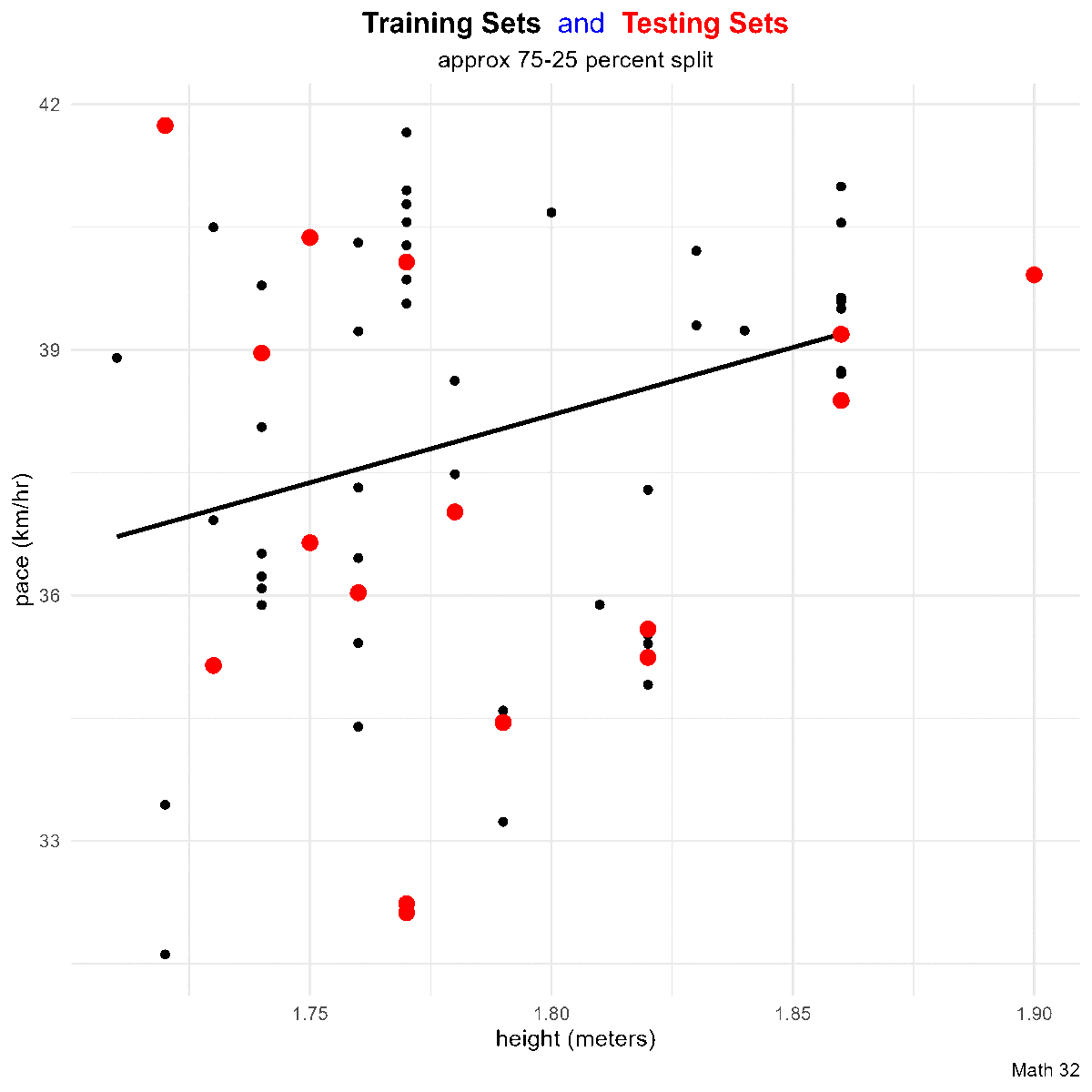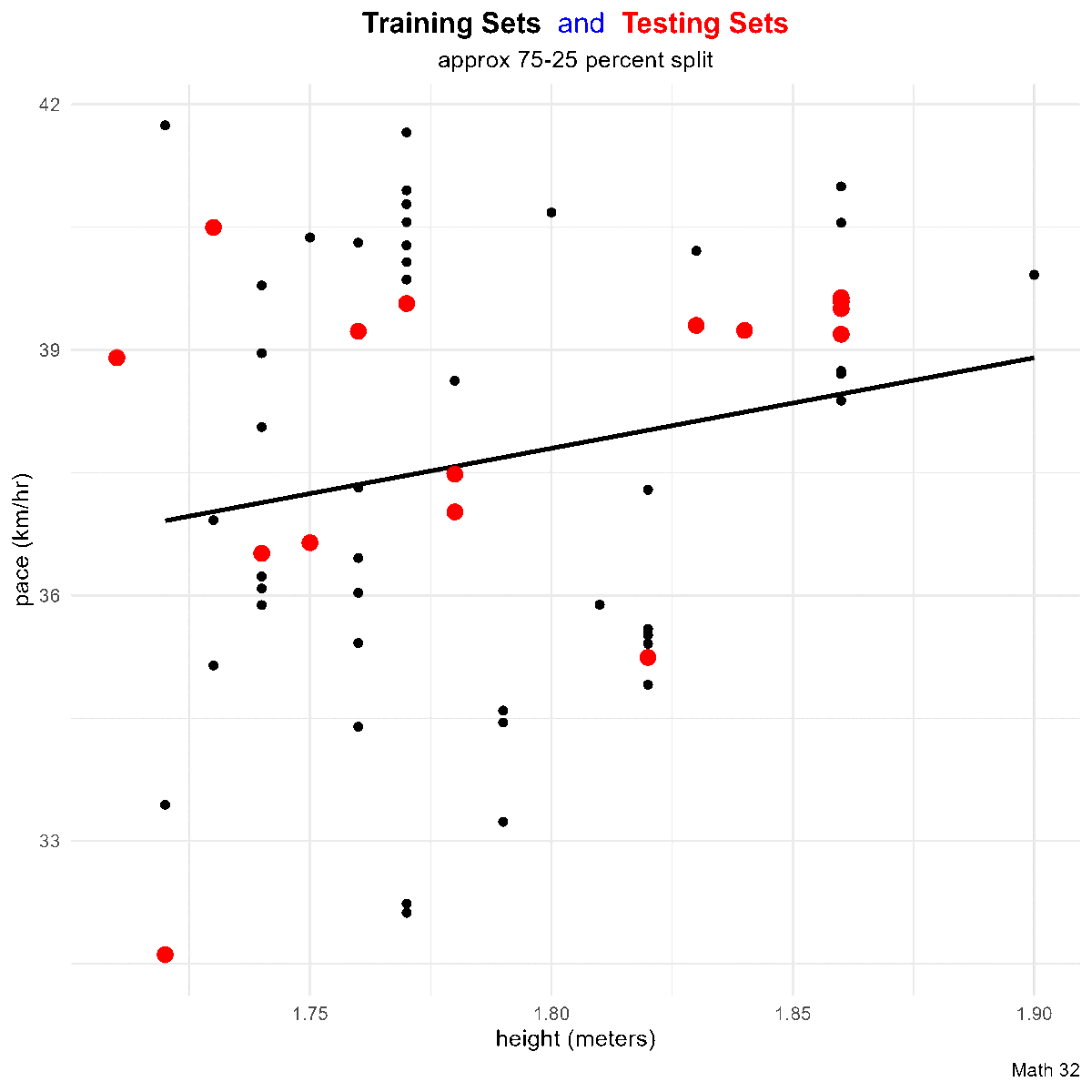
Residuals
Goal: Given a bivariate data set
that ``best fits’’ the data. Note that such a line will not go through all of the data (except in linear, deterministic situations), so
- denote
- denote
- then
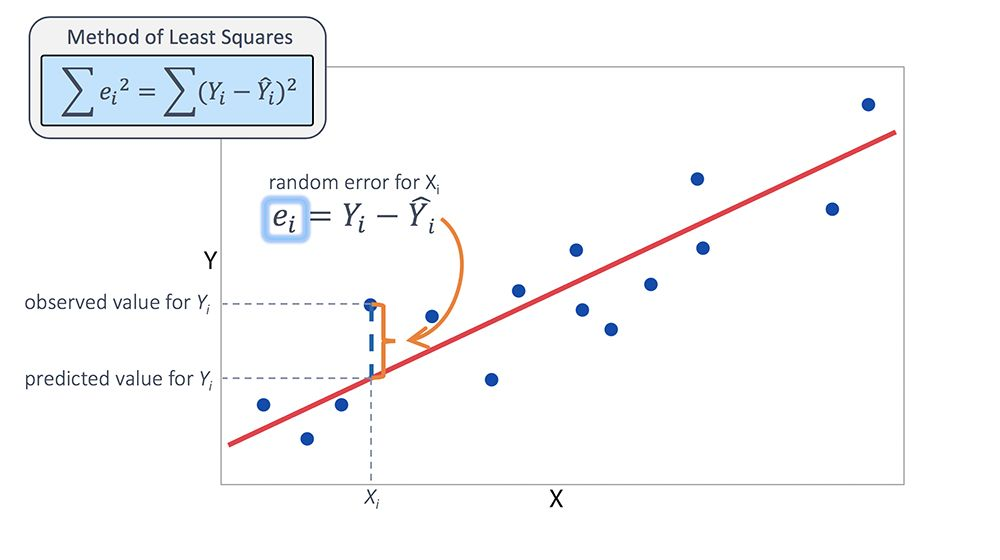
Method of Least Squares
Like our derivation of formulas for variance and standard deviation, scientists decided to square the residuals (focus on size of residuals, avoid positive versus negative signs). Let the total error be
- The ``best-fit line’’ minimizes the error.
- To minimize the error, start by setting the partial derivatives equal to zero:
Linear Regression Model (Another View)
If sample means
- If correlation
- If correlation
Outliers
In a scatterplot, an outlier is a point lying far away from the other data points. Paired sample data may include one or more influential points, which are points that strongly affect the graph of the regression line.
ggplot
The geom_smooth layer is a quick way to draw the linear regression graph in ggplot.
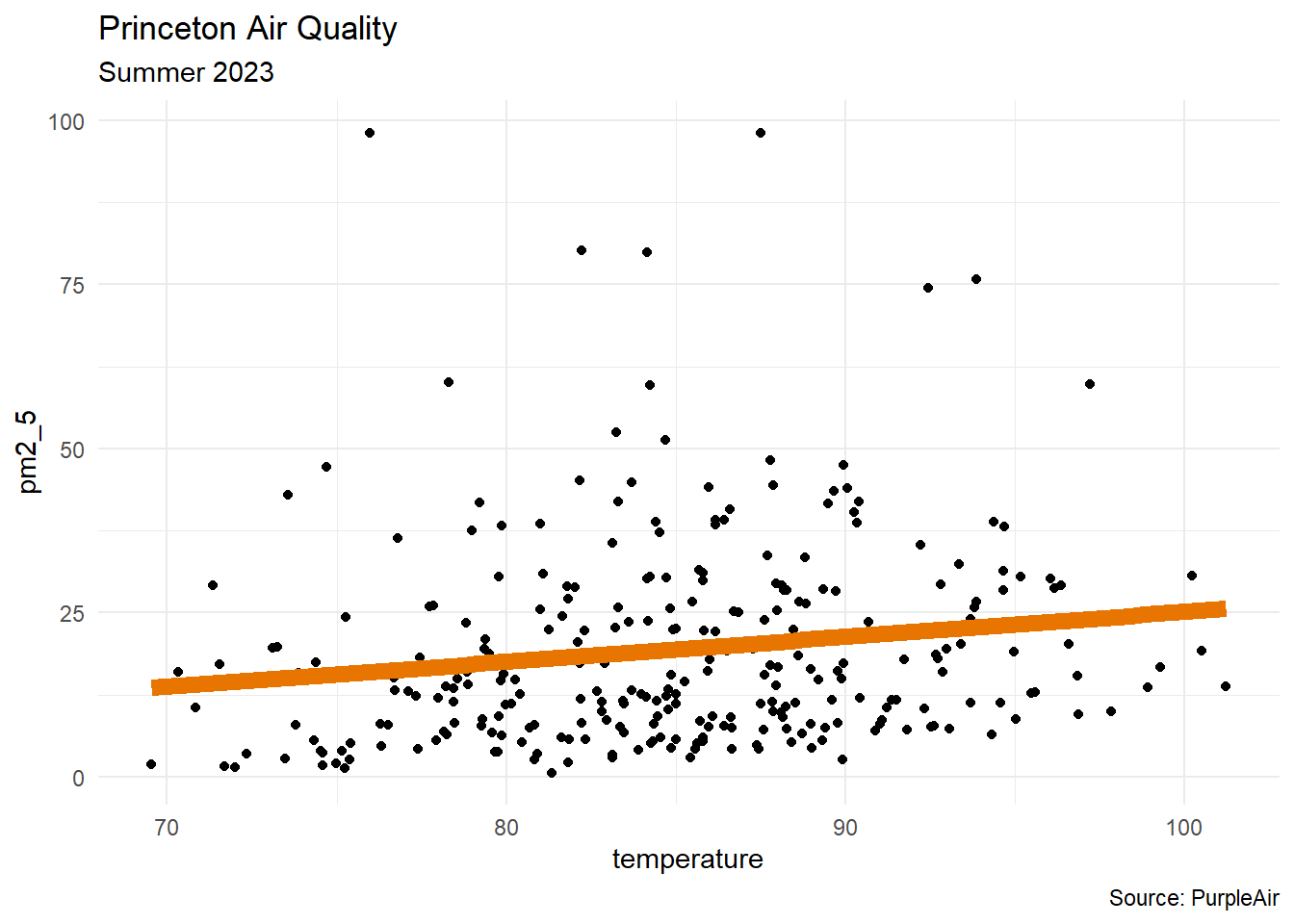
df |>
ggplot(aes(x = temperature, y = pm2_5)) +
geom_point() +
geom_smooth(method = "lm", color = "#e77500",
linewidth = 3, se = FALSE) +
labs(title = "Princeton Air Quality",
subtitle = "Summer 2023",
caption = "Source: PurpleAir") +
theme_minimal()Model
model1 <- lm(pm2_5 ~ temperature, data = df)model1
Call:
lm(formula = pm2_5 ~ temperature, data = df)
Coefficients:
(Intercept) temperature
-12.9066 0.3805 - Interpretation: for every one-degree increase in temperature, the PM2.5 level increases by 0.3805
Prediction
Predict the PM2.5 level for a 78-degree day.
predict(model1,
newdata = data.frame(temperature = 78)) 1
16.77266 
Think about what is meant by linear regression. Draw a large area for a graph (
Multivariate Linear Regression
response variable (
predictor variables
model2 <- lm(pm2_5 ~ temperature + humidity,
data = df)Describe the regression coefficients for the two predictor variables (hint: rates of change).
moderndive::get_regression_table(model2)# A tibble: 3 × 7
term estimate std_error statistic p_value lower_ci upper_ci
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 intercept -10.8 15.7 -0.684 0.495 -41.8 20.2
2 temperature 0.367 0.156 2.35 0.019 0.06 0.674
3 humidity -0.02 0.093 -0.214 0.831 -0.203 0.163
Predict the PM2.5 level for a 78-degree day where the humidity is 50 percent.
predict(model2,
newdata = data.frame(temperature = 78,
humidity = 50)) 1
16.86311 Categorical Variables
response variable (
predictor variables
model3 <- lm(pm2_5 ~ temperature + day_part,
data = df)moderndive::get_regression_table(model3)# A tibble: 5 × 7
term estimate std_error statistic p_value lower_ci upper_ci
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 intercept -42.8 16.8 -2.54 0.012 -76.0 -9.68
2 temperature 0.68 0.184 3.69 0 0.317 1.04
3 day_part: midnight 5.06 2.89 1.75 0.081 -0.628 10.7
4 day_part: morning 8.48 3.29 2.57 0.011 2.00 15.0
5 day_part: noon 4.19 2.68 1.56 0.12 -1.10 9.47- Predict the PM2.5 level for a 60-degree morning.
- Predict the PM2.5 level for a 75-degree evening.
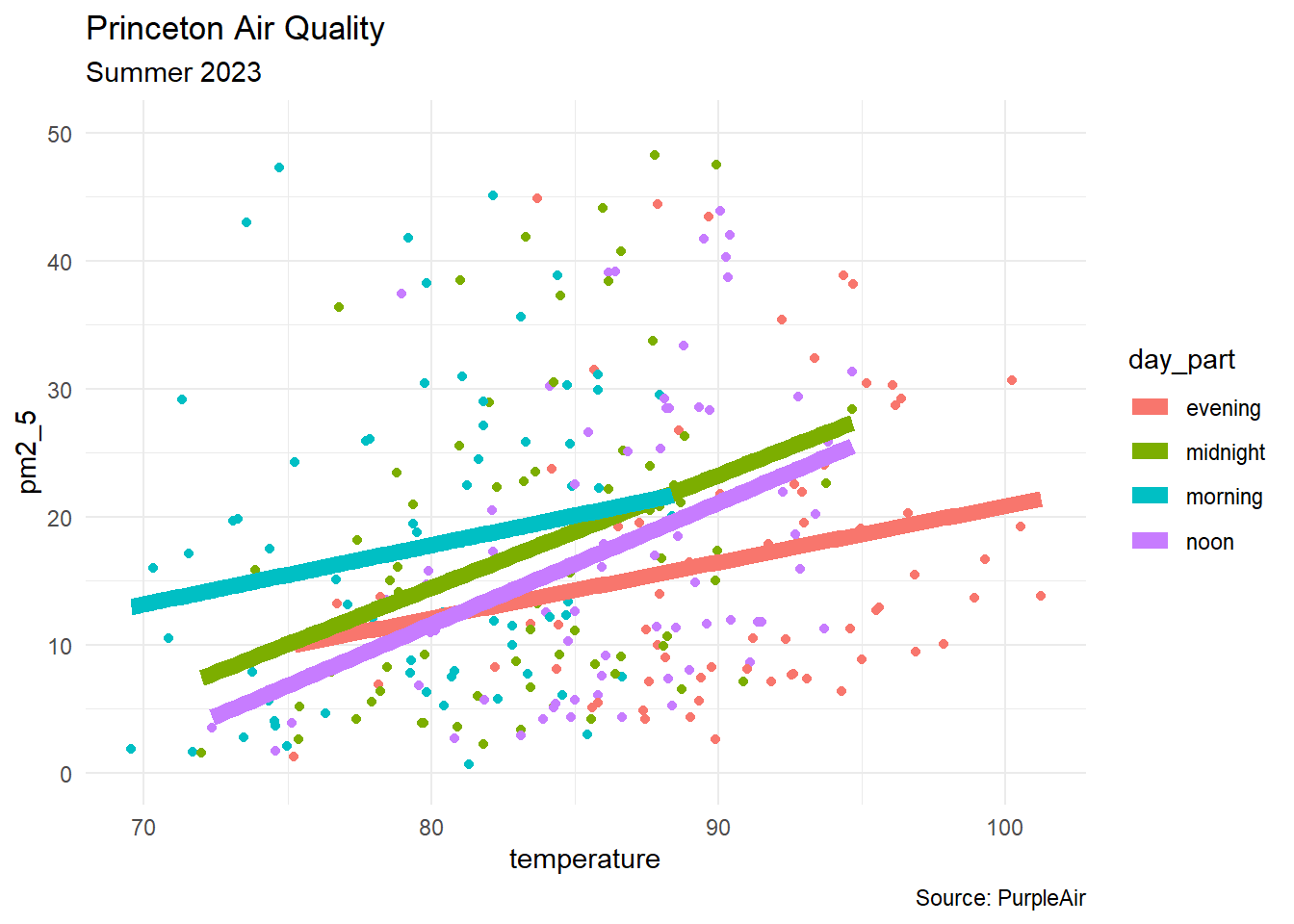
df |>
group_by(day_part) |>
ggplot(aes(x = temperature, y = pm2_5,
color = day_part, group = day_part)) +
geom_point() +
geom_smooth(aes(color = day_part), method = "lm",
linewidth = 3, se = FALSE) +
labs(title = "Princeton Air Quality",
subtitle = "Summer 2023",
caption = "Source: PurpleAir") +
theme_minimal() +
ylim(0,50)predict(model3,
newdata = data.frame(temperature = 60,
day_part = "morning")) 1
6.448983 predict(model3,
newdata = data.frame(temperature = 75,
day_part = "evening")) 1
8.176292 Looking Ahead
To Consider
- How do we know that the predictions are reliable?
- How do we know which model to choose?
- How do we know which variables to use?
More Metrics
get_regression_table(model3)# A tibble: 5 × 7
term estimate std_error statistic p_value lower_ci upper_ci
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 intercept -42.8 16.8 -2.54 0.012 -76.0 -9.68
2 temperature 0.68 0.184 3.69 0 0.317 1.04
3 day_part: midnight 5.06 2.89 1.75 0.081 -0.628 10.7
4 day_part: morning 8.48 3.29 2.57 0.011 2.00 15.0
5 day_part: noon 4.19 2.68 1.56 0.12 -1.10 9.47get_regression_summaries(model3)# A tibble: 1 × 9
r_squared adj_r_squared mse rmse sigma statistic p_value df nobs
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 0.046 0.033 235. 15.3 15.5 3.47 0.009 4 291Book

Thanks!
- Derek Sollberger
- Lecturer of Data Science